The Company Where Every Team Shares One Brain
When support, engineering, and sales share the same AI layer, information stops getting trapped in silos. Here's what that looks like, and why almost nobody is doing it yet.
Free AI Readiness Survey
How ready is your company for AI? Take our 3-minute assessment and get a personalized readiness report.
Let me paint a scenario that I keep coming back to.
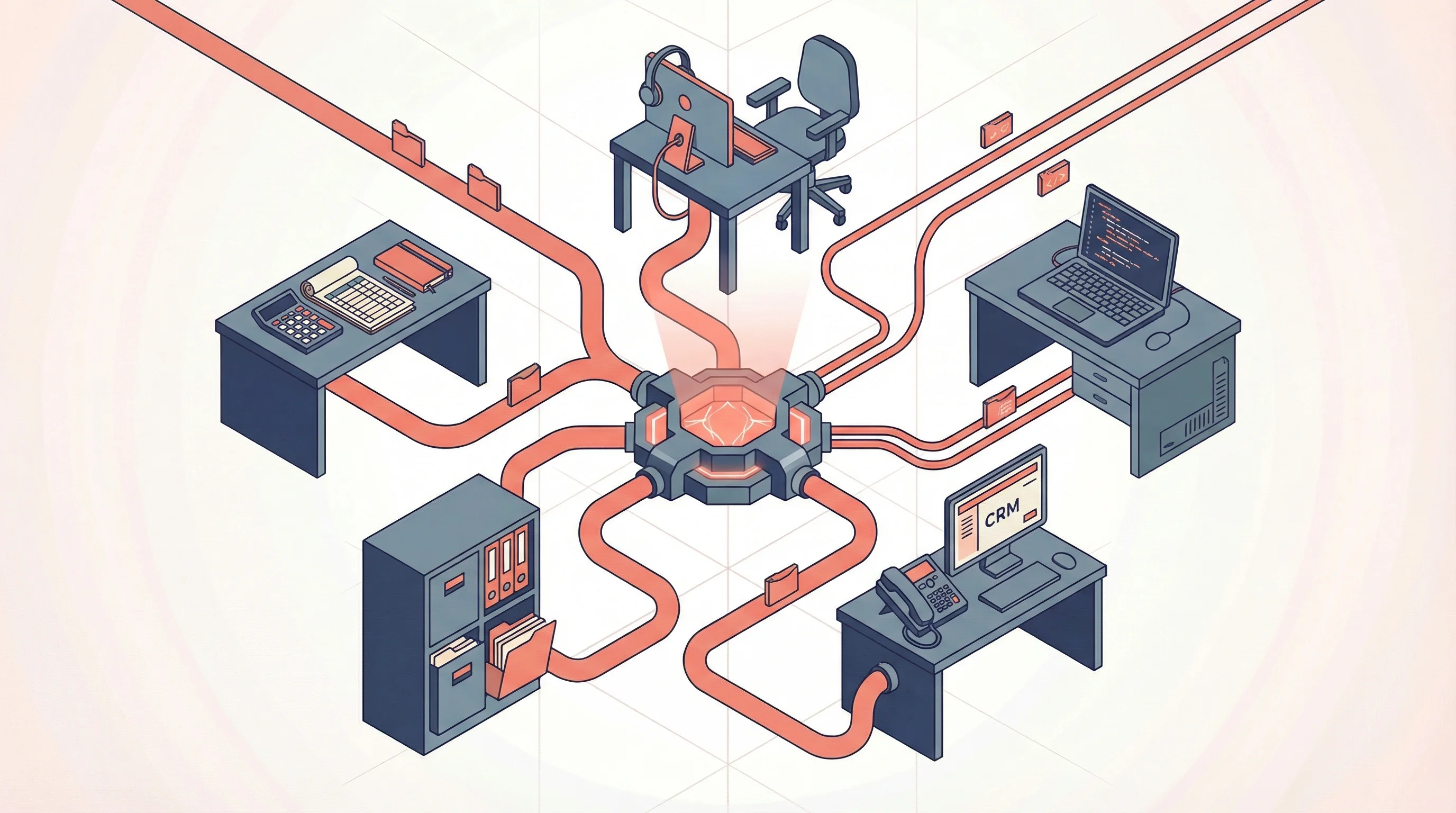
Monday morning. A support agent gets a message from a customer: a feature in the billing module is returning wrong totals on invoices with multiple discount codes. The agent opens the company's AI assistant, describes the issue, and relays a few follow-up answers.
Then the AI does something no human support agent could do in five minutes. It checks Jira for known issues. Nothing matches. It pulls up the ticket creation guidelines from Notion, reads the relevant billing module code, and finds the likely culprit: a function that applies discounts sequentially instead of on the original subtotal. It creates a Jira ticket with reproduction steps, the specific function and file reference, and a severity assessment. The support agent reviews it, confirms the details, and submits.
From there, an automated workflow kicks in. The AI checks the codebase, prepares a root cause analysis and proposed fix in the company's documentation, and an assigned developer reviews the plan. The fix is straightforward, so an AI coding agent picks it up, drafts the code change, and opens a pull request. A developer reviews it. The tech lead approves before it ships. No AI-generated code ships without human sign-off.
That same afternoon, a salesperson asks the AI to prep for a client meeting. The AI compiles the brief, but adds a flag: "The billing module has a known bug affecting multi-discount invoices (BILL-2847). A fix is in progress but not yet deployed. Avoid demoing discount stacking until the patch ships."
The salesperson adjusts the demo plan. The client never sees the broken feature. Nobody had to send a Slack message, attend a standup, or forward an email. Support's knowledge reached engineering's backlog and sales' meeting prep through one shared layer.
Every component of that scenario is available as of March 2026. The infrastructure connecting your AI to Jira, Notion, and the codebase is production-ready and deployed at scale. The real question is why almost nobody is doing it yet. That's what this article is about, and it's what I think about every day at BrainBlend AI, where we help companies build exactly this kind of cross-team AI integration.
What Organizational Silos Actually Cost

When I talk to companies about connecting their teams through AI, the first reaction is always "why bother? Our current setup works fine."
It doesn't. You just can't see the cost.
Poor data quality alone costs the US economy an estimated $3.1 trillion per year, according to IBM. Poor workplace communication costs roughly $12,506 per employee per year. Employees waste 5.3 hours every week waiting for data from colleagues or recreating information that already exists somewhere in the company.
As of 2025, 90% of IT leaders say data silos create business challenges, and 83% say integration delays equate directly to lost revenue. Companies have tried ERPs, shared databases, Slack channels, cross-functional meetings. Those helped at the margins. But they all require humans to actively push information across boundaries. Someone has to remember to forward the email, mention it in the standup, or post the update in the right channel.
And AI adoption is making it worse. According to a 2025 enterprise AI survey by Writer, 68% of executives report that generative AI has created tension between IT and other departments. Marketing has one AI tool, sales has another, engineering has three. Most companies are replicating the silo problem inside their AI strategy.
Why Individual AI Tools Are Not Enough

The conversation about AI in companies is stuck on individual productivity. Faster writing. Faster coding. Faster analysis. Every team gets their own AI tool, every worker becomes a bit more efficient, and the company declares an AI strategy. That's the wrong frame entirely.
A study tracking 443 million hours of workplace activity across 163,000 employees found that after AI adoption, time spent on email went up 104%, messaging went up 145%, and focused work sessions dropped 9%. 77% of employees in an Upwork study say AI tools have added to their workload. 81% of C-suite leaders admit they've increased worker demands in response.
This is the Jevons Paradox: when you make individuals faster, the organization responds by piling on more individual work. Giving people better tools without changing how the organization works just creates overwhelmed individuals.
Cross-team AI changes the equation because it reduces coordination overhead itself: the meetings, the Slack threads, the email chains that exist only to move information from one team to another. You're not making each person do more. You're eliminating the relay work that nobody wanted to do in the first place. When teams share the same AI infrastructure, support's bug report becomes engineering's action plan becomes sales' meeting prep. Not because someone forwarded an email, but because the system connects them.
Who Is Already Doing This
The technical foundation is a protocol called MCP (Model Context Protocol), a standardized interface that lets any tool plug into your AI without a custom integration for each one. As of March 2026, there are 38+ pre-built connectors for tools like Jira, Slack, Notion, Salesforce, HubSpot, GitHub, Google Workspace, and dozens more. OpenAI, Microsoft, Google, Amazon, and Vercel have all integrated MCP support.
Block (the company behind Square) is the clearest example at scale. They deployed MCP across 12,000 employees in 15 job functions within two months, connecting Snowflake, GitHub, Jira, Slack, Google Drive, and 50+ internal platforms. Engineers, salespeople, fraud analysts, designers, and non-technical employees all use the same shared AI layer. One employee analyzed 80,000 sales leads in one hour instead of days. Cognizant is deploying the same pattern to up to 350,000 employees globally.
What This Looks Like Across the Whole Company
The support-to-engineering-to-sales scenario in the opening is just one thread. When the infrastructure is in place, the same pattern plays out everywhere.
Product + Marketing + Sales. Product ships a feature. The release notes trigger the AI to draft a customer-facing announcement. Marketing's configuration adjusts the messaging for different channels. Sales gets a one-pager on how to position the feature in upcoming calls. Right now, sales-marketing misalignment is estimated to cost businesses more than $1 trillion each year, and Forrester found that 60-70% of B2B marketing content goes completely unused by sales. The information exists. It just doesn't flow.
Finance + Operations. End-of-quarter reporting. The AI pulls data from the data warehouse, cross-references with project timelines, and identifies discrepancies between budgeted and actual spend. The CFO gets a summary with flagged anomalies. Operations gets an early warning about projects running over budget, before the formal review where everyone pretends they didn't know.
HR + Engineering. A new hire starts. The AI checks which team they're joining, pulls the tech stack from the engineering wiki, generates a personalized onboarding doc, and creates the relevant accounts. From day one, the new hire can ask the AI questions and get answers that match how the team actually works, not generic responses.
The Hard Parts

If this all sounds too clean, it's because I haven't talked about the hard parts yet.
Accountability. When AI agents create tickets, draft pull requests, and prepare documents across teams, who's responsible when something goes wrong? The answer has to involve human-in-the-loop checkpoints for high-stakes actions, clear audit trails, and defined ownership. AI handles the information relay, but a human owns each decision point.
The service desk trap. AI service desks report impressive numbers: high ticket deflection, halved resolution times. But employees are often more frustrated, because the chatbot resolves a ticket by sending a knowledge base article the employee already tried. Ticket closed, metrics look great, but the laptop still won't connect to the VPN. This is what happens when AI optimizes a single team's metrics without cross-organizational awareness. The fix: measure outcomes across teams, not just within them.
Stale information. If AI treats shared information as ground truth and that information is outdated, errors propagate faster and further than they would through human communication. A wrong assumption in one team's documentation becomes "fact" across the whole organization. Obsidian Security data shows AI agents are routinely granted 10x more access than they actually use, and a proof-of-concept attack demonstrated how a malicious support ticket could use an AI agent to exfiltrate internal data through prompt injection. These risks need real governance.
None of these problems are unsolvable. But they're real, and any company that ignores them will get burned.
How to Actually Get There
Find your champions and your skeptics. You need both. Champions experiment and build the first integrations. But the biggest skeptic who gets convinced becomes your most credible internal advocate, because they surface the real concerns that make the implementation actually stick. BCG research found that teams with managers who actively use AI themselves see up to 4x higher adoption rates.
Start with a pain point, not a vision. Do not try to "transform the company with AI." Find one specific, measurable problem where information doesn't flow between teams. Ticket handoff from support to engineering. Feature announcements from product to marketing. Build one integration. Measure the result. Expand from there. Ask teams what they actually need. The answer is almost never "an AI strategy." It's usually something like "I need to know when engineering ships a fix for the bug my customer reported."
Unify the stack. Get teams on the same AI platform. One set of connections. One shared configuration. This is harder than it sounds, but it's the only path that avoids rebuilding silos inside the AI layer. The alternative is every team picking their own tools, and you're right back where you started.
Give teams space to figure it out. The companies where AI adoption actually works give teams freedom to experiment. The ones that mandate daily AI usage tied to performance metrics end up with people prompting nonsense to hit quota. Freedom and trust produce results. Mandates produce theater.
Invest in organizational readiness. According to RAND, over 80% of AI projects fail, roughly twice the rate of non-AI IT projects. That's not a technology problem. It's an organizational problem: data quality, process clarity, team alignment. Enterprises with a formal AI strategy report 80% success rates versus 37% for those without one.
I should be transparent: this is exactly what BrainBlend AI does. We help organizations do the assessment, the infrastructure setup, and the team alignment that makes the technology actually stick. I have skin in this game. But the scenario in the opening is what genuinely drives this work.
The Company That Knows What It Knows
The promise is not that AI will run your company. It's that your company will finally know what it knows.
Critical information is still locked in people's heads, buried in Slack threads, scattered across tools that don't talk to each other. Someone in support knows about a bug that sales doesn't. Someone in engineering knows about a limitation that product hasn't accounted for. A shared AI layer doesn't replace any of those people. It makes sure their knowledge reaches the people who need it, when they need it.
The technology is not the bottleneck. The bottleneck is organizational willingness to change how information flows. But the companies that figure it out will operate at a speed that siloed organizations simply cannot match. Not because their people are faster, but because their knowledge actually flows.
Ready to build AI that works?
Whether you're just getting started or scaling an existing initiative, we can help your team move faster and get real ROI.
Let's talk